Every Cycle Counts on a 6510: Microsoft Multiplan
Foreword
I’ve been doing some software archaeology and reverse engineering Microsoft Multiplan for the Commodore 64. The original goal was nebulously retro-vulnerability research, but I ended up getting lost on the way and finding a couple totally awesome/unexpected topics.
- A copy protection scheme that uses intentional disk corruption as a fingerprint
- A machine independent bytecode interpreter, with a dispatch loop that rewrites its own instructions each cycle
Lab Environment
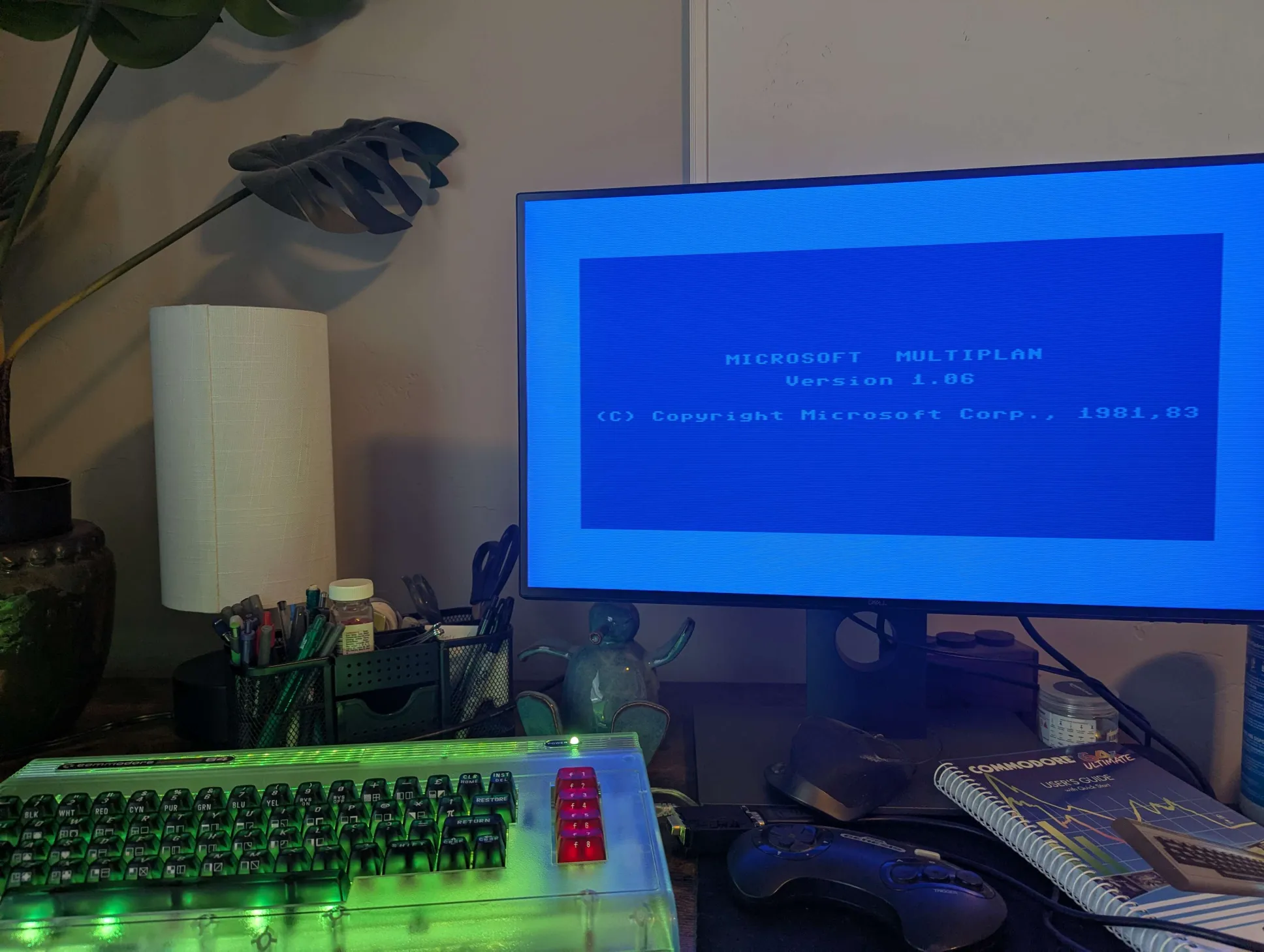
- Commodore 64 Ultimate II+ with DMA read/write API
- Microsoft Multiplan v1.06
- Python 3 + Capstone (MOS65XX disassembly)
- Custom tooling for D64 sector chain following, REL file editing, memory snapshots
Background
Multiplan was an early spreadsheet software. It was Microsoft’s answer to VisiCalc, and it predated Excel by years. Multiplan was distributed widely across many platforms, with the C64 port being published by HesWare in 1984.
While reverse engineering it, I noticed an interesting architectural decision: beyond its abstraction layers, Multiplan didn’t run native 6502 instructions. The spreadsheet logic was compiled to platform-independent bytecode for a stack-based virtual machine. Only the interpreter was native. This is the approach Microsoft used to port Multiplan across dozens of platforms (CP/M, MS-DOS, Apple II, etc.) without rewriting the application logic each time. This posed an incredibly interesting reverse engineering challenge, since the p-code format was undocumented and no analysis tools existed!
Using a combination of off-the-shelf libraries and bespoke tools, I mapped what I think is the most complete reference of Microsoft’s earliest p-code virtual machine architecture (there are likely mistakes; corrections welcome). I also discovered some really interesting copy protection and CPU optimizations in the process - but first, that copy protection had to be addressed so Multiplan could be run on my machine!
Throughout this post I mention files from the Multiplan floppy distribution. Here’s the abbreviated floppy disk layout:
| File | Type | Size | Purpose |
|---|---|---|---|
| MP | PRG | 44B | BASIC bootstrap |
| MP.CODE | SEQ | 20KB | P-code bytecodes (portable) |
| MP.DATA | SEQ | 6KB | Data tables |
| MP. | PRG | 11.5KB | Native 6502 interpreter + I/O |
| MP.SYS | REL | 24KB | System/config data |
Part 1: Copy Protection
The Boot Sequence
Multiplan boots through a two-stage BASIC loader. The first file MP is a dense/tiny BASIC program:
1 IF O THEN SYS 2996 : REM <5xDEL + "8">
2 O=1 : LOAD"MP.",8,1
The <5xDEL + "8"> after REM are five PETSCII DELETE characters ($14) followed by the digit 8. When you LIST the program, BASIC outputs each byte through CHROUT. The DELETEs erase backwards over :REM6, and the 8 prints in place, so the screen shows SYS 2998 instead of the real address SYS 2996. Anybody casually LISTing the bootstrap to figure out the entry point gets pointed to a different address.
I wonder if this is just a hilarious way to leverage the difference between display and runtime for anti-analysis?
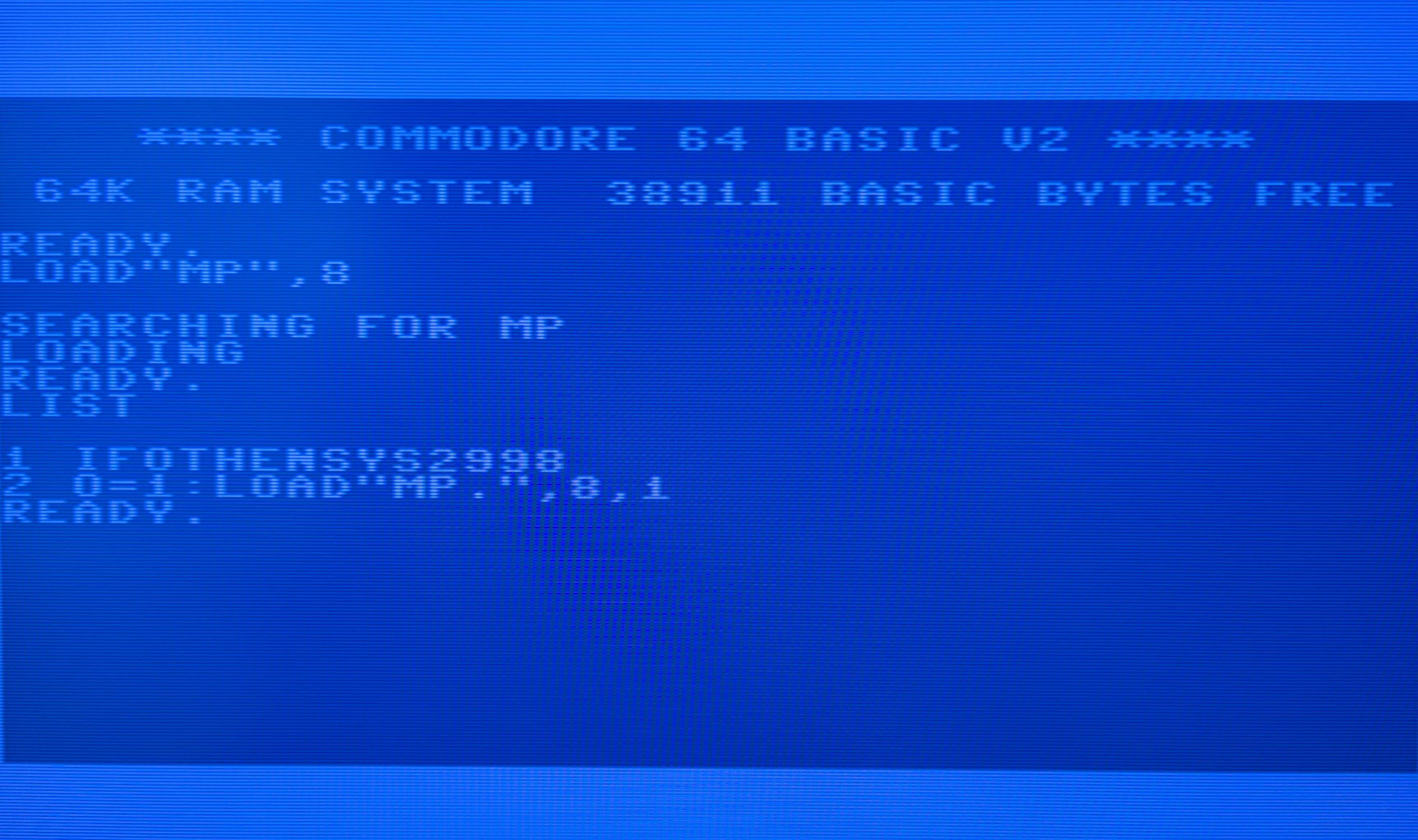
The variable O is a “have I been here before?” flag that exploits a quirk of CBM BASIC: when a running program executes LOAD, BASIC restarts from line 1, but variables survive.
First pass: O doesn’t exist yet (BASIC treats this uninitialized as 0), so IF O is false. Line 2 sets O=1, then LOAD"MP.",8,1 loads the native binary into memory at $0900. BASIC restarts the program.
Second pass: O is still 1 from last time. IF O is true. SYS 2996 executes, jumping to the protection routine at $3500.
The Protection
The protection routine lives at $3500-$35F8 inside MP. and runs in multiple stages. The first two are preamble:
Stage 1 ($3500): Self-locating code. The routine needs to know what address it’s running at, but there’s no “get current PC” instruction on the 6502. The gadget: write an RTS opcode ($60) to $7FFF, then JSR $7FFF. The JSR pushes the return address onto the stack before jumping. The RTS immediately returns. Now the code reads the stack to recover its own return address, specifically the high byte ($35), which tells it what memory page it’s on. It writes this page number into the zero-page locations that the Multiplan runtime expects to be set correctly.
Stage 2 ($352E): RAM sanity check. Writes to $9000 and reads it back. Multiplan uses $9000+ for its workspace, so this verifies the address is actually writable RAM before committing. On a stock C64 this always passes. If it fails (wrong hardware, expansion cartridge mapped over RAM, etc.) the routine bails into sabotage rather than crashing mysteriously later.
Then the protection routines:
If the RAM check passes, execution moves to the disk I/O and verification stages. If anything fails along the way, a branch sends execution to the bail-out routine at $353A.
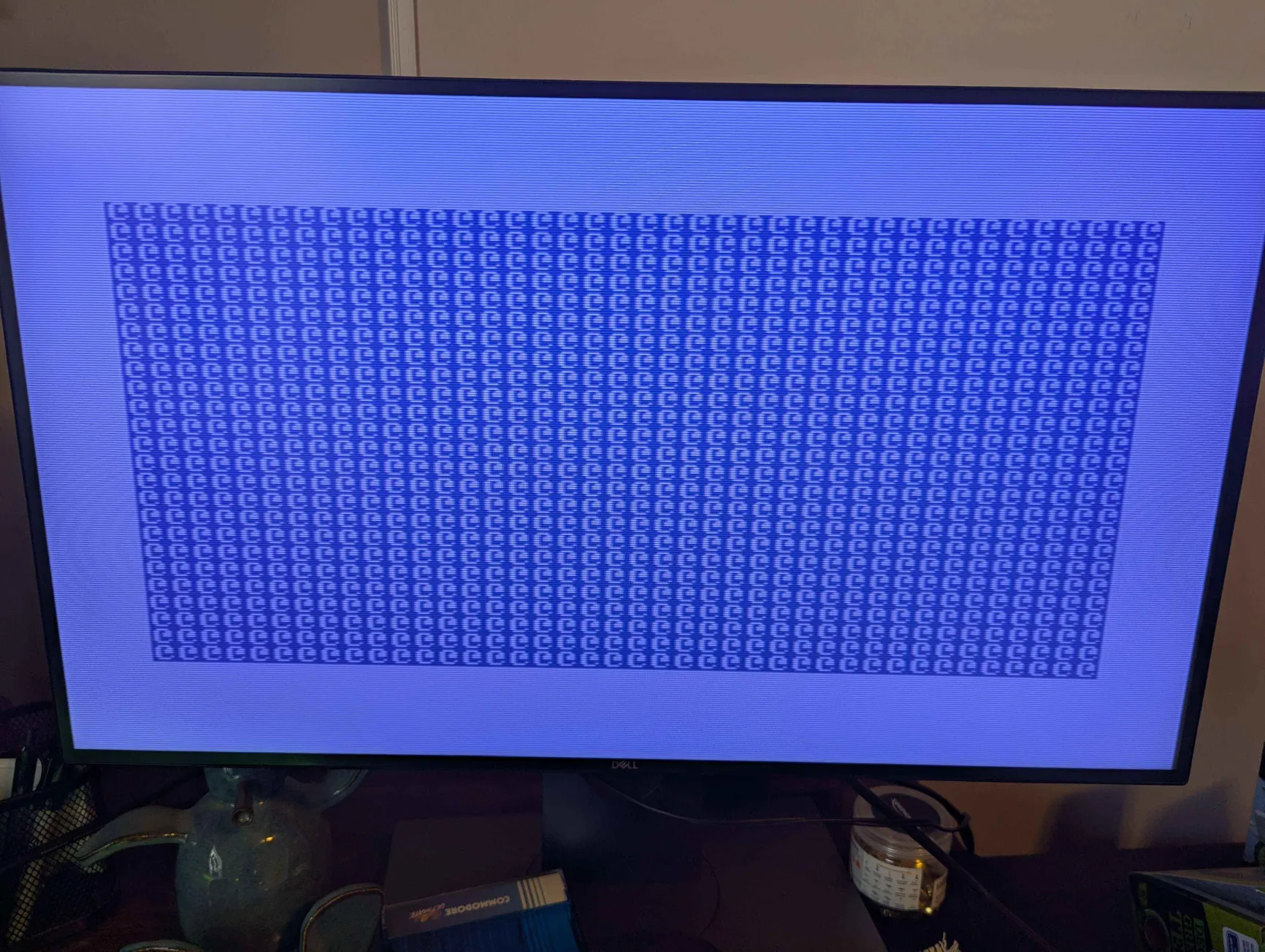
Bail-out ($353A): Fills large regions of memory with whatever value happens to be in A. Corrupts the entire runtime. The observed symptom is an @ character flood on screen as the display routine executes garbage. This code is never reached on a legitimate boot.
Stage 3 ($3549): Opens two I/O channels to the 1541 drive through the C64’s KERNAL (the built-in OS). A command channel (logical file 15) and a data channel (logical file 3, direct-access buffer).
Stage 4 ($357B): The actual check.
$357B: JSR $65B0 ; send "U1:3 0 01 02" → read T1/S2
$357E: BNE $353A ; error? → bail-out
$3580: DEC $65EB ; modify command: sector "2" → "1"
$3583: JSR $65B0 ; send "U1:3 0 01 01" → read T1/S1
$3586: BEQ $353A ; success? → bail-out
Read Track 1, Sector 2. If it fails, the disk is broken, bail-out. Then decrement the sector number in the command string (change 2 to 1) and read Track 1, Sector 1. If it succeeds, the disk is a copy, bail-out.
So best I can tell: the original disk was manufactured with an intentional checksum error on T1/S1. The 1541 drive reports a data block checksum error when reading it. A bit-perfect copy of the disk data would reproduce the sector contents but not the checksum error, because the copy routine recalculates valid checksums. So the original fails to read (correct behavior), copies succeed (bail-out).
Stage 6 ($35A7): Cleanup. Restores default KERNAL vectors, then patches the entry point at $0BB4 from JMP $3500 (protection) to JMP $2CE7 (Multiplan init). The protection erases itself after passing.
My Bypass
I patched $3549 from 20 90 FF (JSR $FF90, start of I/O setup) to 4C A7 35 (JMP $35A7, skip to cleanup). This preserves stage 1 and stage 2 initialization while jumping over the disk I/O and protection check.
Part 2: The Self-Modifying Dispatch Loop
Multiplan’s p-code interpreter reads one bytecode, looks up a handler in a jump table, dispatches to it, and loops. This is the innermost loop of the entire application. It runs for every single p-code instruction, many times per spreadsheet operation. When trying to understand the mechanism backing this I stumbled on what I think is a super cleverly optimized interpreter dispatch loop.
On the 6510, writing a fast bytecode interpreter is hard. There’s no fast way to say “load a byte from the address stored in this variable,” or “jump to the address stored in this variable.” Some interesting self-modifying code emerges when you try to optimize the interpreter’s dispatcher as tightly as possible.
Indirect addressing modes exist (LDA ($11),Y costs 5 cycles, LDA ($11,X) costs 6) but absolute addressing (LDY $AE87) costs only 4 cycles. The author of this dispatch loop realized they could shave cycles off by encoding variable data directly into the instruction’s absolute address. JMP is similarly constrained in that there’s no computed JMP where you can say “jump to the address in register X.” By writing the dispatch target as the absolute destination (JMP $1234, 3 cycles) instead of indirect (JMP ($0059), 5 cycles) further cycles can be saved.
For Multiplan this ends up looking like the following (living in zero page at $000F-$0025):
$000F: PHA ; 48 push A (result from previous handler)
$0010: LDY $xxxx ; AC xx xx fetch opcode from p-code stream
$0013: INC $11 ; E6 11 advance p-code PC
$0015: BNE +2 ; D0 02 skip if no page boundary cross
$0017: INC $12 ; E6 12 handle page cross
$0019: LDA $0900,Y ; B9 00 09 look up handler address (low byte)
$001C: STA $24 ; 85 24 write it into the JMP below
$001E: LDA $0A00,Y ; B9 00 0A look up handler address (high byte)
$0021: STA $25 ; 85 25 write it into the JMP below
$0023: JMP $xxxx ; 4C xx xx dispatch: target was just written
Two instructions in this loop modify themselves on every dispatch:
LDY $xxxx at $0010: The two bytes at $0011/$0012 are simultaneously the LDY instruction’s address operand AND the p-code program counter. When INC $11 executes at $0013, it changes $0011 from (say) $87 to $88. The next time the CPU reaches $0010, the instruction has become LDY $AE88 instead of LDY $AE87. It fetches the next bytecode because its own operand was rewritten out from under it.
JMP $xxxx at $0023: The two bytes at $0024/$0025 are simultaneously the JMP instruction’s target address AND the handler address just looked up from the jump table. STA $24 and STA $25 write the handler’s address into the bytes that JMP is about to read. The CPU jumps wherever the table lookup decided, with zero indirection overhead.
Counting Cycles
To quantify what the self-modifying code actually saves, here’s what a naive dispatcher could look like:
; Naive dispatch (not zero page, indirect addressing)
PHA ; 3 push A (result from previous handler)
LDY #$00 ; 2 set index to zero
LDA ($11),Y ; 5 fetch opcode through pointer
TAY ; 2 move opcode to Y for table index
INC $11 ; 6 advance PC low byte (not zero page: 6 cycles)
BNE +2 ; 2 skip if no page cross
INC $12 ; 6 carry into high byte
LDA $0900,Y ; 4 look up handler address (low byte)
STA $59 ; 4 store to temp (not zero page: 4 cycles)
LDA $0A00,Y ; 4 look up handler address (high byte)
STA $5A ; 4 store to temp
JMP ($0059) ; 5 indirect jump through pointer
;--
; 41 cycles
Now the Multiplan version. Self-modifying LDY instead of indirect fetch, self-modifying JMP instead of indirect jump, and the whole loop in zero page for faster read-modify-write:
; Multiplan dispatch (zero page, self-modifying)
PHA ; 3 push A (result from previous handler)
LDY $xxxx ; 4 fetch opcode (operand IS the PC)
INC $11 ; 5 advance PC low byte (zero page: 5 cycles)
BNE +2 ; 2 skip if no page cross
INC $12 ; 5 carry into high byte
LDA $0900,Y ; 4 look up handler address (low byte)
STA $24 ; 3 write into JMP below (zero page: 3 cycles)
LDA $0A00,Y ; 4 look up handler address (high byte)
STA $25 ; 3 write into JMP below
JMP $xxxx ; 3 direct jump (target was just written)
;--
; 31 cycles
Side by side, instruction for instruction (common path, no page cross):
| Step | Naive | Cycles | Multiplan | Cycles | Savings |
|---|---|---|---|---|---|
| Push result | PHA | 3 | PHA | 3 | 0 |
| Fetch opcode | LDY #0 + LDA ($11),Y + TAY |
9 | LDY $xxxx (self-mod) |
4 | 5 |
| Advance PC | INC (abs) + BNE |
8 | INC (zp) + BNE |
7 | 1 |
| Table lookup | LDA abs,Y x2 |
8 | same | 8 | 0 |
| Store target | STA $59 + STA $5A (abs) |
8 | STA $24 + STA $25 (zp) |
6 | 2 |
| Dispatch | JMP ($0059) indirect |
5 | JMP $xxxx direct (self-mod) |
3 | 2 |
| 41 | 31 | 10 |
That’s 10 cycles saved per dispatch. Of those: 7 come from self-modification (5 on the fetch, 2 on the jump) and 3 come from zero-page placement (1 on INC, 2 on the STA pair). On a 1MHz CPU, that’s 10 microseconds off every single p-code instruction, a ~24% reduction in interpreter overhead.
The handler address table is split across two 256-byte pages ($0900 for low bytes, $0A00 for high bytes) specifically to enable this. Both lookups use the same Y register with LDA $0900,Y and LDA $0A00,Y. A combined table would need two loads with different index offsets.
The 23-byte loop is originally part of MP. at $31DD-$31F3. During boot, it’s copied to zero page. This is why the “relocated block” exists in the initialization sequence: to place the interpreter’s hottest code in the fastest memory on the machine.
Despite all this Multiplan still feels slow as fuck on a C64. I shudder to think what it felt like before they optimized it 😆
Part 3: Claude as a Reverse Engineering Partner
This project was done almost entirely in collaboration with Claude Code. I treated Claude as a collaborator that could build its own tools on top of existing building blocks, then use those tools to drive the next phase of analysis.
The Toolchain
Over the course of the project Claude wrote many Python scripts iteratively as research demanded them. Notable examples:
-
pcode_disasm.py: p-code disassembler. -
pcode_emu.py: p-code emulator. Full stack machine implementation with ~90 opcode handlers, IO_SYS coroutine dispatch, and memory-mapped I/O. -
rel_editor.py: REL file editor that follows CBM side-sector chains to map record+offset to D64 disk bytes. Essential because REL files scatter across non-contiguous sectors. -
readmem.py: DMA memory tools that talk to the C64 Ultimate’s REST API. Read arbitrary memory regions from the running C64 for before/after diffing during file loads. -
build_helloworld.py: the proof that the toolchain works end-to-end. Assembles custom p-code, follows the MP.CODE sector chain in the D64, patches the bytes at the right offsets across sector boundaries, and produces a bootable disk image. The C64 executes our p-code and puts “HELLO WORLD FROM CUSTOM P-CODE” on screen.
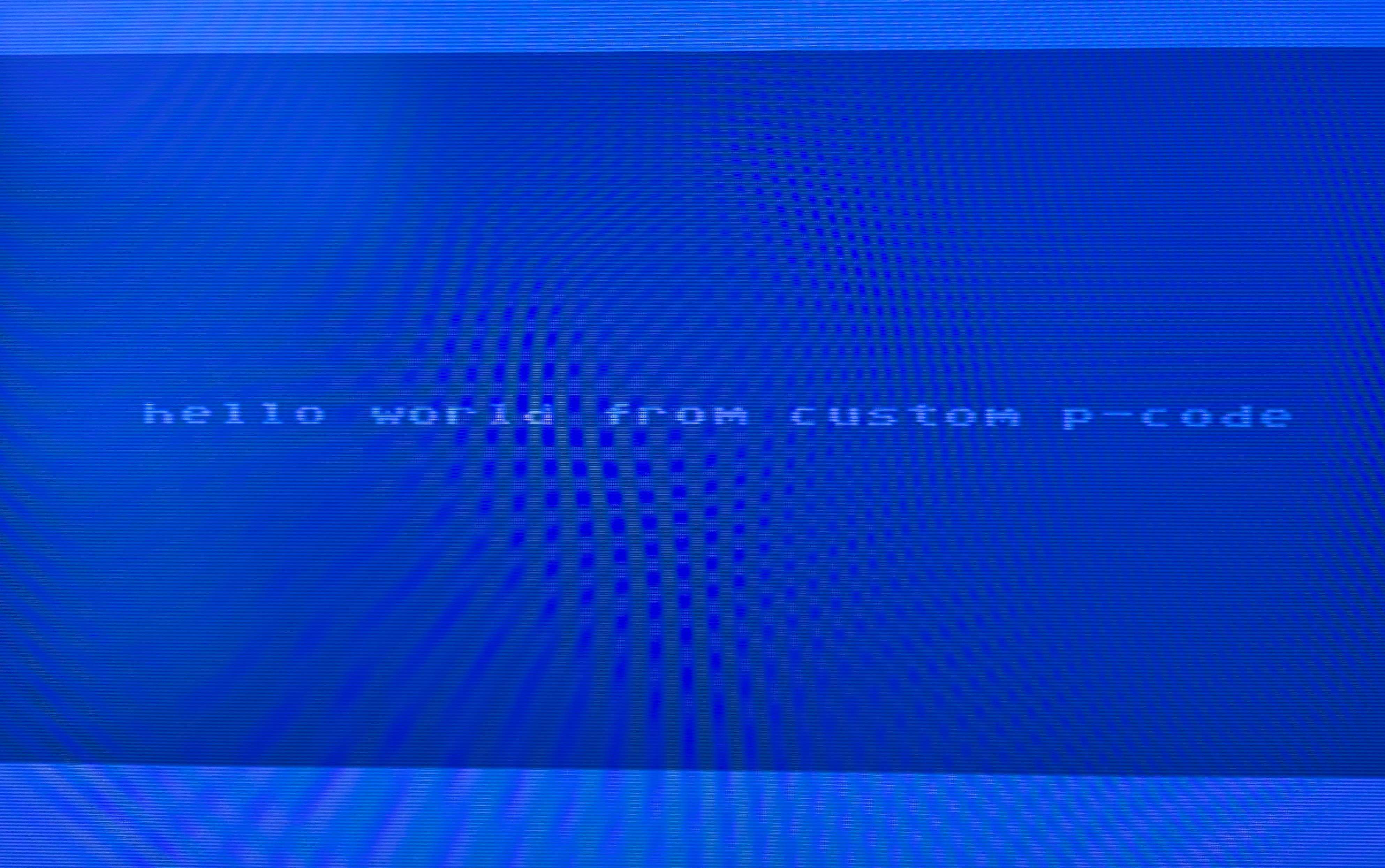
None of these existed before the project. Each one was built when the research hit a wall that required a new capability, and each one builds on standard components (Capstone for 65XX disassembly, requests for the DMA API, Python for binary analysis). It composed small, correct tools from parts it understood.
What Worked Well
Iterative hypothesis testing. The workflow that produced the most value was: form a theory about the VM’s behavior, Claude writes a tool to test it, run it, results disprove the theory, form a new one.
DMA truth. The C64 Ultimate’s memory read API helps check theory against reality. Claude would predict what should be at a memory address, I’d read it from the live machine, and mismatches drove deeper investigation.
Expanding on composable building blocks. Claude is good at writing tools that compose existing libraries correctly. There was a lot of format-parsing code that was easy to get subtly wrong, and having Claude write a first draft and then fix it against test cases was faster than writing it by hand.
What Didn’t
Speculative analysis without verification. When Claude tried to reason about the VM’s behavior without having concrete methods to test assertions, it got things wrong. Static analysis of the 6502/p-code alone wasn’t sufficient.
Wrap-up
This was awesome diving into some really old software protection mechanisms, and even more so diving into arcane optimization tricks for squeezing the most out of a tiny chip. If there’s interest in fully reverse engineering the ’80s p-code format I may clean up and publish the scripts I used on Multiplan.
keep it old-school, until next time 🎉
darbonzo