Reverse Engineering WeeperVM 2 by Ben_Lolo
Challenge Link 1 and Challenge Link 2
Foreword
Thanks Ben_Lolo once again for putting together a fantastic reverse engineering challenge - it was a great way to showcase a whole slew of interesting subjects:
- Anti-debug evasion on linux
- pwndbg enhanced GDB scripting
- Reverse engineering a custom ISA
- Navigating embedded machine code obfuscation
- Crypto cracking
Goals
- Reverse engineer the VM instruction set and architecture
- Recover a flag
Lab Environment
- Ubuntu 24.04.3 LTS
- IDA Pro 9.1
- Pwndbg 2025.05.30
- Python 3.12.9
- GDB 16.2
Initial Dynamic Analysis
I first chose to analyze the application using strace -if ./WeeperVM--Level_2 to get a sense for the early behaviors the binary exhibits. Note -f to ensure child processes / threads are followed, and -i to display the program counter at time of syscall.
strace Insight 1: Embedded Bytecode
The application performs a self-read near a high entropy block that was correctly assumed to be its bytecode (0x61e0). It’s likely the application performs its anti-patching via /proc/self/exe as well, but I didn’t ever need to explicitly verify.
[pid 25473] [0000000000011cf8] open("/proc/self/exe", O_RDONLY) = 3
[pid 25473] [0000000000011cf8] read(3, "\177ELF\2\1\1\0\0\0\0\0\0\0\0\0\2\0>\0\1\0\0\0\2004\1\0\0\0\0\0"..., 64) = 64
[pid 25473] [0000000000011cf8] lseek(3, 24672, SEEK_SET) = 24672
strace Insight 2: Time-based Thread Stop Detection
The target repeatedly reads the current time, which is often a behavior of applications that rely on time-based anti-tracing.
[pid 25474] [0000000000011cf8] gettimeofday({tv_sec=1757866270, tv_usec=950499}, NULL) = 0
strace Insight 3: TracerPid Detection
The target reads /proc/self/status, which in proximity to receiving a kill signal is a strong anti-debug indicator.
[pid 25474] [0000000000011cf8] open("/proc/self/status", O_RDONLY) = 4
strace Insight 4: Memory Dumping / Manipulation Detection
The target uses the inotify subsystem to monitor /proc/self/mem, which indicates protection from memory based introspection and tampering.
[pid 25475] [0000000000011cf8] inotify_add_watch(5, "/proc/self/mem", IN_ACCESS <unfinished ...>
Evading Anti-debug, Anti-trace, and Anti-patch
Note that most anti-* checks the target performs originate from a single offset 0x11cf8, which indicates the virtualized code executes its operating system supported operations through a single opcode. The virtualized syscall opcode is a powerful single point of failure for anti-analysis features.
Fake procfs and no-op timestamps
Through the single point in which syscalls flow, I scripted a hook that evades the applications anti-* checks. It does so by redirecting syscalls that rely on procfs instead to the local filesystem, as well as no-op’ing gettimeofday invocations.
Relative to the running target the physical filesystem must have the following structure:
./WeeperVM--Level_2
./zproc/self/exe *1
./zproc/self/status *2
./zproc/self/mem *3
🔔 *1) exe is an unmodified copy of the target
🔔 *2) status is a copy of /proc/<Weeper2_PID>/status with no TracerPid
🔔 *3) mem is an empty file
By doing this: exe always contains expected content, status never reveals TracerPid, and mem never flags inotify callbacks. Additionally with gettimeofday being no-op’d, time Δ after thread stops will always be zero.
# Usage (within pwndbg):
# * starti
# * source evade.py
import pwndbg.dbg
from pwnlib.asm import asm
from pwndbg.aglib import memory
from pwndbg.dbg.gdb import GDB
from pwnlib.context import context
pdgb: GDB = pwndbg.dbg
context.arch = 'amd64'
def bypass_antidebug():
# hook VM syscall opcode -- 6 byte (two opcode) clobber
hook_b = asm("jmp 0x00000000000134E0; nop", 0x0000000000011CF0)
# relocate the clobbered opcodes to the hook body prologue
existing_ops = memory.read(0x0000000000011CF0, len(hook_b))
memory.write(0x0000000000011CF0, hook_b)
# write hook body in `.text` slack space
# the hook redirects procfs to local fs by clobbering leading slashes with 'z'
# it also no-ops gettimeofday to avoid time tamper checks
body_b = existing_ops + asm("""
// check syscall number for open, inotify, gettimeofday
cmp rax, 2
je _do_open_hook
cmp rax, 254
je _do_inotify_hook
cmp rax, 96
je _do_noop
jmp _resume
_do_open_hook:
// redirect procfs to local fs by clobbering leading slash with 'z'
cmp dword ptr [rdi], 0x6f72702f
jne _resume
mov byte ptr [rdi], 0x7a
jmp _resume
_do_inotify_hook:
// redirect procfs to local fs by clobbering leading slash with 'z'
cmp dword ptr [rsi], 0x6f72702f
jne _resume
mov byte ptr [rsi], 0x7a
jmp _resume
// restore original control flow
_resume:
jmp 0x0000000000011CF6
_do_noop:
mov rax, 0
jmp 0x0000000000011CF8
""", 0x00000000000134E0 + len(existing_ops))
memory.write(0x00000000000134E0, body_b)
bypass_antidebug()
Virtual Architecture
With both dynamic and static analysis available at this point, I walked the stack frame up from our known “syscall”-esque VM opcode handler to the VM’s main loop. With some renaming and cleanup the main loop (0x102EC) can be understood as follows:
__int64 __fastcall vm_main(unsigned int pc)
{
...
_BYTE decoded_lval[9]; // [rsp+1Eh] [rbp-49Ah] BYREF
_BYTE decoded_rval[9]; // [rsp+27h] [rbp-491h] BYREF
unsigned __int8 *context[3]; // [rsp+30h] [rbp-488h] BYREF
_BYTE regs[64]; // [rsp+48h] [rbp-470h] BYREF
_BYTE stack[1072]; // [rsp+88h] [rbp-430h] BYREF
...
context[0] = regs;
context[1] = stack;
LODWORD(context[2]) = 0; // Flags
...
do
{
...
result = execute_single_op(pc, decoded_opcode, decoded_lval, decoded_rval, context, next_instruction);
...
}
while ( (_DWORD)result != 0xFFFFFF );
The VM components consist of a single readwrite memory range, 16 32-bit registers, a 32-bit callstack, and a flags register. Instructions are variable width, with the first three bytes containing the operation, lvalue flags, and rvalue flags. Large constants and memory config overflow into additional bytes. Instructions are unordered, being followed by an obfuscated (⊕ 0xDC2606) offset to their next instruction. The VM allows for threaded execution, making tracing more difficult at times. Setting the scheduler locking mode of GDB can be helpful, and thread scoped breakpoints can help as well.
Instruction decoding was mostly a cut-and-paste job from IDA with some minor cleanups. This could be simplified, but it wasn’t necessary.
op_b0, op_b1, op_b2 = ROM[pc:pc+3]
lflag = ((op_b1 >> 5 & 3) + 1) * 0x10 | (op_b0 * 0x02 & 2 | op_b1 >> 7) << 2 | op_b0 >> 1 & 3
lval = ROM[pc+3:pc+8]
rflag = (16 * (((op_b2 >> 5) & 3) + 1)) | (op_b1 >> 1) & 3 | (4 * ((op_b2 >> 7) | (2 * op_b1) & 2))
if rflag & 3:
offs = 0
if lflag & 3 == 1:
offs = 1
elif lflag & 2:
offs = lflag >> 4
rval = ROM[pc+3+offs:pc+3+offs+6]
else:
rval = bytearray()
op = (((op_b1 & 0x18) << 0x17) >> 0x18)
op_decoded = (-((op == 8) != (op == 4)) ^ (op_b0 >> 3) ^ op_b2) & 0x1f
# Use decoded opcode
__(pc, op_decoded, (lflag, lval), (rflag, rval), ROM)
# Next opcode
ins_size = lflag >> 4 if (lflag & 0x3) else 0
ins_size += rflag >> 4 if (rflag & 0x3) else 0
encr_offs = int.from_bytes(ROM[pc+ins_size+3:pc+ins_size+6], 'little')
pc = encr_offs ^ 0xDC2606
Control flow is achieved using a flags and dedicated jump and comparison opcodes. Notably certain opcodes also contain conditional forms (i.e. conditional call’s and ret’s)
By convention register state is preserved across subroutines using a specialized mov opcode that derives save addresses by hashing the current stack frame return.
Reverse Engineering Opcodes
The IDA decompiler output for execute_single_op did not spark joy when I read it.

I instead opted to understand opcodes primarily through diffing the VM’s execution state. By capturing the state of the VM before and after unknown opcode(s) execute, their behavior can be understood observationally. Optionally fuzzing the state of the VM beforehand allows for an understanding of how opcodes operate on varied inputs. The following is a script demonstrates slicing state around a single opcode that moves a constant to a register.
Note the addition of a hook to better allow stopping the VM at a specific address, since conditional breakpoints in the host debugger are prohibitively slow (or deadlock-y).
# Usage (within pwndbg):
# * starti
# * source slice_diff.py
# Edit SLICE_START/END and fuzz params to taste
from pathlib import Path
import pwndbg.dbg
from pwnlib.asm import asm
from pwndbg.aglib import memory
from pwndbg.dbg.gdb import GDB
from pwndbg.dbg import BreakpointLocation
import gdb
from pwnlib.context import context
pdgb: GDB = pwndbg.dbg
SLICE_START = 0x00013030
SLICE_END = 0x000027BC
FIRST_BP = 0
SECOND_BP = 0
context.arch = 'amd64'
with (Path(__file__).parent / 'WeeperVM--Level_2').open('rb') as f:
weeper_vm = f.read()
ROM = weeper_vm[0x000061E0:]
def vm_regs(ctx_addr: int) -> list[int]:
reg_addr = int.from_bytes(memory.read(ctx_addr, 8), 'little')
regs = []
for i in range(16):
r = int.from_bytes(memory.read(reg_addr + i * 4, 4), 'little')
regs.append(r)
return regs
def vm_stack(ctx_addr: int) -> list[int]:
stack_addr = int.from_bytes(memory.read(ctx_addr + 8, 8), 'little')
stack = []
for i in range(270):
m = int.from_bytes(memory.read(stack_addr + i * 4, 4), 'little')
stack.append(m)
return stack
def vm_mem() -> bytes:
mem_addr = int.from_bytes(memory.read(0x0000000000015040, 8), 'little')
return memory.read(mem_addr, 0x100000)
def vm_flags(ctx_addr: int) -> int:
return int.from_bytes(memory.read(ctx_addr + 16, 8), 'little')
def fuzz_vm_state(ctx_addr: int):
# reg_addr = int.from_bytes(memory.read(ctx_addr, 8), 'little')
# for i in range(16):
# memory.write(reg_addr + i * 4, (0x12345678 + i).to_bytes(4, 'little'))
# stack_addr = int.from_bytes(memory.read(ctx_addr + 8, 8), 'little')
# for i in range(270):
# memory.write(stack_addr + i * 4, (0x66666660 + i).to_bytes(4, 'little'))
# mem_addr = int.from_bytes(memory.read(0x0000000000015040, 8), 'little')
# buf = bytearray(0x100000)
# for i in range(0x100000):
# buf[i] = i % 256
# memory.write(mem_addr, buf)
pass
def print_state_diff(
before_regs: list[int], before_stack: list[int], before_mem: bytes, before_flags: int,
after_regs: list[int], after_stack: list[int], after_mem: bytes, after_flags: int):
for i in range(16):
if before_regs[i] != after_regs[i]:
print(f'[+] Modified register $r{i}: {before_regs[i]:08x} -> {after_regs[i]:08x}')
for i in range(270):
if before_stack[i] != after_stack[i]:
print(f'[+] Modified stack [0x{i * 4:08x}]: {before_stack[i]:08x} -> {after_stack[i]:08x}')
for i in range(len(before_mem)):
if before_mem[i] != after_mem[i]:
print(f'[+] Modified memory [0x{i:08x}]: {before_mem[i]:02x} -> {after_mem[i]:02x}')
if before_flags != after_flags:
print(f'[+] Modified flags: {before_flags:08x} -> {after_flags:08x}')
print('Diff complete')
async def slice_diff(ec: pwndbg.dbg_mod.ExecutionController):
first = True
with pdgb.selected_inferior().break_at(BreakpointLocation(FIRST_BP)) as first_bp:
with pdgb.selected_inferior().break_at(BreakpointLocation(SECOND_BP)) as second_bp:
while True:
await ec.cont(first_bp)
regs = pdgb.selected_frame().regs()
ctx_addr = int(regs.by_name('r8'))
print(f'[1] Slicing at {int(regs.by_name("rdi")):08x}')
if first:
fuzz_vm_state(ctx_addr)
first = False
before_regs, before_stack, before_mem, before_flags = vm_regs(ctx_addr), vm_stack(ctx_addr), vm_mem(), vm_flags(ctx_addr)
await ec.cont(second_bp)
print(f'[2] Slicing at {int(regs.by_name("rdi")):08x}')
after_regs, after_stack, after_mem, after_flags = vm_regs(ctx_addr), vm_stack(ctx_addr), vm_mem(), vm_flags(ctx_addr)
print_state_diff(before_regs, before_stack, before_mem, before_flags, after_regs, after_stack, after_mem, after_flags)
def bypass_antidebug():
# hook VM syscall opcode -- 6 byte (two opcode) clobber
hook_b = asm("jmp 0x00000000000134E0; nop", 0x0000000000011CF0)
# relocate the clobbered opcodes to the hook body prologue
existing_ops = memory.read(0x0000000000011CF0, len(hook_b))
memory.write(0x0000000000011CF0, hook_b)
# write hook body in `.text` slack space
# the hook redirects procfs to local fs by clobbering leading slashes with 'z'
# it also no-ops gettimeofday to avoid time tamper checks
body_b = existing_ops + asm("""
// check syscall number for open, inotify, gettimeofday
cmp rax, 2
je _do_open_hook
cmp rax, 254
je _do_inotify_hook
cmp rax, 96
je _do_noop
jmp _resume
_do_open_hook:
// redirect procfs to local fs by clobbering leading slash with 'z'
cmp dword ptr [rdi], 0x6f72702f
jne _resume
mov byte ptr [rdi], 0x7a
jmp _resume
_do_inotify_hook:
// redirect procfs to local fs by clobbering leading slash with 'z'
cmp dword ptr [rsi], 0x6f72702f
jne _resume
mov byte ptr [rsi], 0x7a
jmp _resume
// restore original control flow
_resume:
jmp 0x0000000000011CF6
_do_noop:
mov rax, 0
jmp 0x0000000000011CF8
""", 0x00000000000134E0 + len(existing_ops))
memory.write(0x00000000000134E0, body_b)
def hook_ins():
global FIRST_BP, SECOND_BP
# hook VM instructions, call redirection
hook_b = asm("call 0x00000000000136E0", 0x000000000001046A)
memory.write(0x000000000001046A, hook_b)
# write hook body in `.text` slack space
body_b: bytes = asm(f"""
cmp rdi, 0x{SLICE_START:X}
je _do_slice_start
cmp rdi, 0x{SLICE_END:X}
je _do_slice_end
jmp _resume
_do_slice_start:
nop
jmp _resume
_do_slice_end:
nop
_resume:
jmp 0x0000000000010491
""", 0x00000000000136E0)
memory.write(0x00000000000136E0, body_b)
first_idx = body_b.find(b'\x90')
second_idx = body_b.find(b'\x90', first_idx + 1)
FIRST_BP = 0x00000000000136E0 + first_idx
SECOND_BP = 0x00000000000136E0 + second_idx
def main():
gdb.execute("starti")
gdb.execute("bc")
bypass_antidebug()
hook_ins()
pdgb.selected_inferior().dispatch_execution_controller(slice_diff)
main()

Disassembling
With opcodes understood and instructions decoded I opted to write a quick-and-dirty x86 inspired disassembler for the VM. It maintains a list of visited addresses to avoid unbounded disassembly looping and makes no attempt at semantically correct control flow graph presentation.
from pathlib import Path
import sys
HIWORD = lambda x: (x >> 16) & 0xFFFF
HIBYTE = lambda x: (x >> 8) & 0xFF
PROC_STACK: list[int] = [0]
FRAME_RETS: dict[int, int] = {0: 0}
FRAME_RET = 0
SEEN_ADDRESSES: set[int] = set()
def decode_val(param: tuple[int, bytes], lparam: tuple[int, bytes] | None = None) -> str:
nval = param[1]
rmc = param[0] & 3
width = (param[0] >> 2) & 3
csiz = param[0] >> 4
decoded = ''
post = {
1: 'b',
2: 'w',
3: 'd',
}
if rmc == 0x1:
# Reg
r = nval[0]
if r > 15:
raise ValueError(f'Invalid register: {r}')
decoded += f'r{r}.{post[width]}'
elif rmc == 0x2:
# Memory
if nval[0] & 0x40:
width = (nval[0] >> 2) & 3
r1 = (nval[1] >> 2) & 0xF
r2 = (nval[1] >> 6) | ((nval[0] * 4) & 0xC)
decoded += f'm[r{r1}+r{r2}].{post[width]}'
else:
c = ''
r = -1
if nval[0] & 0x80:
r = nval[0] & 0xF
csiz -= 1
if csiz > 0:
const = int.from_bytes(nval[1:1+csiz], 'big')
if const != 0:
if r != -1:
c += f'+'
c += f'{const:02X}'
if r != -1:
r = f'r{r}'
else:
r = ''
decoded += f'm[{r}{c}].{post[width]}'
elif rmc == 3:
# Constant
assert csiz > 0
const = int.from_bytes(nval[0:csiz], 'big')
decoded += f'0x{const:X}'
return decoded
def dasm_op(pc: int, op_decoded: int, lparam: tuple[int, bytes], rparam: tuple[int, bytes], ROM: bytes) -> tuple[bool, int]:
print(f'{pc:08X}: ', end='')
if pc == 0x0000FDF1:
print(f'\t[DEBUG] {ROM[pc:pc+12].hex()}')
pass
decoded_lval = decode_val(lparam)
decoded_rval = decode_val(rparam, lparam)
if op_decoded == 0x0:
print(f'mov ', end='')
elif op_decoded == 0x2:
v305 = int(decoded_lval, 16)
decoded_addr = ((FRAME_RET >> 8) ^ (FRAME_RET ^ 0x4571cbe2) * 0x3466875) & 0xFFFFFFFF
decoded_addr = ((FRAME_RET >> 0x10) ^ (decoded_addr * 0x3466875)) & 0xFFFFFFFF
decoded_addr = ((FRAME_RET >> 0x18) ^ (decoded_addr * 0x3466875)) & 0xFFFFFFFF
decoded_addr = ((v305 ^ (decoded_addr * 0x3466875)) * 0x857c4b2) & 0xfffe
print(f'mov_enc [{decoded_addr:08X}], {decoded_rval}')
return True
elif op_decoded == 0x3:
v305 = int(decoded_rval, 16)
decoded_addr = ((FRAME_RET >> 8) ^ (FRAME_RET ^ 0x4571cbe2) * 0x3466875) & 0xFFFFFFFF
decoded_addr = ((FRAME_RET >> 0x10) ^ (decoded_addr * 0x3466875)) & 0xFFFFFFFF
decoded_addr = ((FRAME_RET >> 0x18) ^ (decoded_addr * 0x3466875)) & 0xFFFFFFFF
decoded_addr = ((v305 ^ (decoded_addr * 0x3466875)) * 0x857c4b2) & 0xfffe
print(f'mov_enc {decoded_lval}, [{decoded_addr:08X}]')
return True
elif op_decoded == 0x4:
print(f'add ', end='')
elif op_decoded == 0x5:
print(f'sub ', end='')
elif op_decoded == 0x6:
print(f'imul ', end='')
elif op_decoded == 0x7:
print(f'idiv ', end='')
elif op_decoded == 0x8:
print(f'mod ', end='')
elif op_decoded == 0x9:
print(f'cmp ', end='')
elif op_decoded == 0xA:
suffix = ''
if decoded_rval == '':
suffix = 'mp'
else:
if int(decoded_rval, 16) == 0x6:
suffix += 'ne'
elif int(decoded_rval, 16) & 0x2:
suffix += 'l'
elif int(decoded_rval, 16) & 0x4:
suffix += 'g'
elif int(decoded_rval, 16) & 0x1:
suffix += 'e'
addr = int(decoded_lval, 16)
PROC_STACK.append(addr)
FRAME_RETS[addr] = FRAME_RET
print(f'j{suffix} {decoded_lval}')
return True
elif op_decoded == 0xb:
subroutine = int.from_bytes(ROM[pc+3:pc+6], 'big')
ret = int.from_bytes(ROM[pc+6:pc+9], 'little') ^ 0xDC2606
PROC_STACK.append(subroutine)
FRAME_RETS[subroutine] = ret
suffix = ''
if decoded_rval != '':
if int(decoded_rval, 16) == 0x6:
suffix += 'ne'
elif int(decoded_rval, 16) & 0x2:
suffix += 'l'
elif int(decoded_rval, 16) & 0x4:
suffix += 'g'
elif int(decoded_rval, 16) & 0x1:
suffix += 'e'
print(f'call{suffix} {subroutine:08X} -> {ret:08X}\n', end='')
return True
elif op_decoded == 0xc:
suffix = ''
if decoded_lval != '':
if int(decoded_lval, 16) == 0x6:
suffix += 'ne'
elif int(decoded_lval, 16) & 0x2:
suffix += 'l'
elif int(decoded_lval, 16) & 0x4:
suffix += 'g'
elif int(decoded_lval, 16) & 0x1:
suffix += 'e'
print(f'ret{suffix}')
return True
else:
print(f'ret ', end='')
elif op_decoded == 0xd:
print(f'abort ', end='')
elif op_decoded == 0xe:
print(f'and ', end='')
elif op_decoded == 0xf:
print(f'or ', end='')
elif op_decoded == 0x10:
print(f'xor ', end='')
elif op_decoded == 0x11:
print(f'shl ', end='')
elif op_decoded == 0x12:
print(f'shr ', end='')
elif op_decoded == 0x14:
if decoded_lval == '0x20':
decoded_lval += ' ; sys_open'
elif decoded_lval == '0x21':
decoded_lval += ' ; sys_read'
elif decoded_lval == '0x11':
decoded_lval += ' ; sys_getpid'
elif decoded_lval == '0x13':
decoded_lval += ' ; sys_kill'
elif decoded_lval == '0x14':
decoded_lval += ' ; sys_gettimeofday'
elif decoded_lval == '0x33':
decoded_lval += ' ; sys_futex'
elif decoded_lval == '0x24':
decoded_lval += ' ; sys_seek'
elif decoded_lval == '0x22':
decoded_lval += ' ; sys_write'
elif decoded_lval == '0x30':
decoded_lval += ' ; sys_inotify_init'
elif decoded_lval == '0x31':
decoded_lval += ' ; sys_inotify_add_watch'
elif decoded_lval == '0x9D':
decoded_lval += ' ; sys_prctl'
elif decoded_lval == '0x10':
decoded_lval += ' ; sys_nanosleep'
elif decoded_lval == '0x23':
decoded_lval += ' ; sys_close'
else:
raise NotImplementedError()
print(f'syscall ', end='')
elif op_decoded == 0x15:
print(f'bswap ', end='')
elif op_decoded == 0x16:
print(f'bit_mirror ', end='')
elif op_decoded == 0x17:
print(f'merge_srchi_destlo ', end='')
elif op_decoded == 0x18:
print(f'merge_srclo_desthi ', end='')
elif op_decoded == 0x19:
print(f'rol ', end='')
elif op_decoded == 0x1a:
print(f'ror ', end='')
elif op_decoded == 0x1b:
print(f'thread ', end='')
subroutine = int(decoded_lval, 16)
ret = int.from_bytes(ROM[pc+3:pc+6], 'little') ^ 0xDC2606
PROC_STACK.append(subroutine)
FRAME_RETS[subroutine] = ret
else:
print(f'unk_{op_decoded:02x} ', end='')
decode_val(lparam)
decode_val(rparam, lparam)
return False
if len(decoded_lval) > 0:
print(f'{decoded_lval}', end='')
if len(decoded_rval) > 0:
print(f', {decoded_rval}', end='')
print('')
return True
def main():
global FRAME_RET
with (Path(__file__).parent / 'WeeperVM--Level_2').open('rb') as f:
weeper_vm = f.read()
ROM = weeper_vm[0x000061E0:]
while len(PROC_STACK) > 0:
pc = PROC_STACK.pop(0)
FRAME_RET = FRAME_RETS.get(pc)
if pc in SEEN_ADDRESSES:
print(f'[DEBUG] Already seen address: {pc:08X}', file=sys.stderr)
continue
if pc != 0:
print('\n' + ('-' * 40) + '\n')
while pc != 0xffffff:
SEEN_ADDRESSES.add(pc)
op_b0, op_b1, op_b2 = ROM[pc:pc+3]
lflag = ((op_b1 >> 5 & 3) + 1) * 0x10 | (op_b0 * 0x02 & 2 | op_b1 >> 7) << 2 | op_b0 >> 1 & 3
lval = ROM[pc+3:pc+8]
rflag = (16 * (((op_b2 >> 5) & 3) + 1)) | (op_b1 >> 1) & 3 | (4 * ((op_b2 >> 7) | (2 * op_b1) & 2))
if rflag & 3:
offs = 0
if lflag & 3 == 1:
offs = 1
elif lflag & 2:
offs = lflag >> 4
rval = ROM[pc+3+offs:pc+3+offs+6]
else:
rval = bytearray()
op = (((op_b1 & 0x18) << 0x17) >> 0x18)
op_decoded = (-((op == 8) != (op == 4)) ^ (op_b0 >> 3) ^ op_b2) & 0x1f
dasm_op(
pc,
op_decoded,
(lflag, lval),
(rflag, rval),
ROM
)
if op_decoded == 0xc and lflag == 0x10:
break
ins_size = lflag >> 4 if (lflag & 0x3) else 0
ins_size += rflag >> 4 if (rflag & 0x3) else 0
encr_offs = int.from_bytes(ROM[pc+ins_size+3:pc+ins_size+6], 'little')
pc = encr_offs ^ 0xDC2606
if __name__ == '__main__':
main()
Selective “Lifting”
Rather than lifting to IR I opted to use claude to “vibe-lift” certain routines in the disassembled target to python. While not nearly as powerful as translating the VM bytecode to something like LLVM IR or BNIL, this approach was fast and most importantly “good-enough” to solve the challenge.
Example CLAUDE.md
# Instructions
This is a source code recovery project, you help convert x86-esque assembly snippets to python in two steps.
1. First naively replicate the behavior of the snippet in python.
2. Perform a simplication pass to make the snippet feel less like a code emulator, and more like native python.
# Notes
Call and ret instructions appended with 'l' 'g', and 'ne' are conditional.
Look in `examples.py` for how syscall, byte_swap, and bit_mirror opcodes should be implemented.
DWORD constants are big-endian.
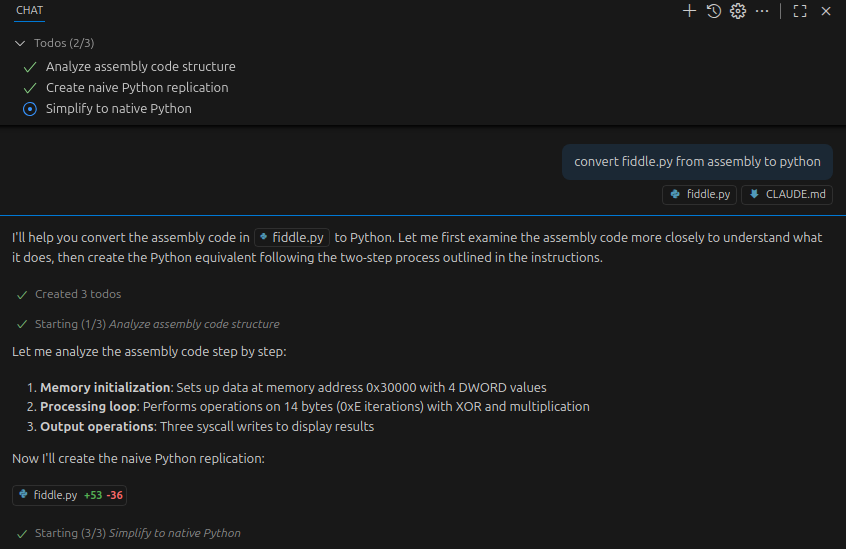
This provided me with trivial decryption of stack strings, and reasonably readable implementations of algorithmic subroutines (with some minor fixups required). Example output for the subroutine 00000ECE, which prints the target’s encrypted “success” message:
# outputs decrypted stack string: `Very wise :)`
def converted_clean():
"""Clean, readable version showing what the algorithm actually does"""
# The algorithm processes initial data and generates a transformed sequence
initial_data = bytes([0x56, 0x33, 0x13, 0xCE, 0x18, 0x27, 0xD4, 0x4B,
0x10, 0xA0, 0x78, 0x65, 0xE9, 0x3B, 0x00, 0x00])
result = [initial_data[0]] # Keep first byte
# Transform bytes 1-13 using: (index-1)*0x52 XOR current_dword XOR previous_dword
for i in range(1, 14):
if i + 3 < len(initial_data):
curr_dword = struct.unpack('<I', initial_data[i:i+4])[0]
prev_dword = struct.unpack('<I', initial_data[i-1:i+3])[0]
transformed = ((i-1) * 0x52 ^ curr_dword ^ prev_dword) & 0xFF
result.append(transformed)
# Create output with ANSI escape codes for colored text
result_str = ''.join(chr(b) for b in result)
print(f"\x1b[1;37m{result_str}\x1b[0m", end='')
Flag Finding
After disassembling and using claude to decrypt stack strings I worked back from the success conditions to understand the intended solution. The flag check is implemented in four steps:
- Process input with a custom xxhash-based hasher
- Seed a Mersenne Twister with 32-bit hasher output
- Twist for each DWORD in its state vector (
0x270) - Compare each DWORD to an obfuscated (hardcoded) PRNG state
0000AFEF: call 0000AE50 -> 00010806 ; xxhash(ish) input
00010806: mov r0.d, r4.d
00013804: call 00007632 -> 000061AE
000061AE: mov r10.d, 0xE2000
0000137A: mov r11.d, r0.d
000103EB: call 000029EE -> 0000B8E8 ; seed PRNG
0000B8E8: call 00007632 -> 0000A376
0000A376: mov r14.d, 0x0
00016856: mov r10.d, 0xE2000
00005CC6: call 00019936 -> 000133CD ; generate PRNG long
000133CD: mov r10.d, r4.d
0001644C: mov r11.d, r14.d
000025A0: call 00004059 -> 00015954 ; compare long to hardcoded
Identification of the algorithms was largely done by comparing hardcoded magic values to reference implementations:
- Identifying xxhash: https://grep.app/search?q=0x85EBCA77
- Identifying Mersenne Twister: https://grep.app/search?q=0x9908B0DF
Recovering PRNG State
To be able to work towards our target state output from xxhash(ish), we need to know what the target state seed for the PRNG is. I started by deobfuscating one of the vector entry checks that had a single finite solution.
00004059: mov r4.d, 0x0
000015B4: cmp r11.d, 0x0
0000F719: je 0xCC18 ; <---- non-finite solution set
00017590: cmp r11.d, 0x1
0000D38C: je 0xDD6C ; <---- finite solution set
...
0000DD6C: bit_mirror r5.d, r10.d
00004EEA: mov r5.d, r5.b
000113DC: bit_mirror r5.b, r5.b
0000071D: mov r6.d, r10.d
00017A6A: add r5.d, r6.d
0000C75B: mov r6.d, r10.w
00000E6E: shr r6.d, 0x8
00008213: sub r5.d, r6.d
0000C788: cmp r5.d, 0xDFD6220C
0000BD46: retne
The following is a lazy brute force over all 32-bit integers that recovers the constant in a few minutes.
# pypy3 brute.py
# solution: 0xdfd6214e
import multiprocessing as mp
def bit_mirror(int_: int, width: int) -> int:
int_ &= (1 << width) - 1
return int(('{:0' + str(width) + 'b}').format(int_, width=width)[::-1], 2)
def hash_ladder_0000DD6C(r10: int) -> int:
r5 = bit_mirror(r10, 32)
r5 = bit_mirror(r5, 8)
r6 = r10
r5 = (r5 + r6) & 0xffffffff
r6 = r10 & 0xFFFF
r6 >>= 8
r5 = (r5 - r6) & 0xffffffff
return r5 == 0xDFD6220C
def check_range(start, end):
results = []
for i in range(start, end):
if hash_ladder_0000DD6C(i):
results.append(i)
return results
if __name__ == '__main__':
chunk_size = (0xFFFFFFFF + 1) // 8
ranges = [(i * chunk_size, (i + 1) * chunk_size) for i in range(8)]
ranges[-1] = (ranges[-1][0], 0xFFFFFFFF + 1) # Adjust last range
with mp.Pool(8) as pool:
results = pool.starmap(check_range, ranges)
for result_list in results:
for i in result_list:
print(f'solution: 0x{i:08x}')
Now to recover the PRNG seed I iterated over all 32-bit integers once again to check for a second state vector entry of 0xdfd6214e. The Mersenne Twister (MTRand) implementation was a claude translation of Evan Sultanik’s mtwister. This implementation lines up extremely well with the implementation used by the VM.
# pypy3 brute_mersenne.py
# solution: 0xb48db866
from mt import MTRand
import multiprocessing as mp
def mt_check(r10: int) -> int:
rng = MTRand(r10)
rng.gen_rand_long()
r5 = rng.gen_rand_long()
return r5 == 0xdfd6214e
def check_range(start, end):
results = []
for i in range(start, end):
if mt_check(i):
results.append(i)
print(f'crack: 0x{i:08x}')
return results
if __name__ == '__main__':
chunk_size = (0xFFFFFFFF + 1) // 8
ranges = [(i * chunk_size, (i + 1) * chunk_size) for i in range(8)]
ranges[-1] = (ranges[-1][0], 0xFFFFFFFF + 1)
with mp.Pool(8) as pool:
results = pool.starmap(check_range, ranges)
for result_list in results:
for i in result_list:
print(f'solution: 0x{i:08x}')
Note the use of pypy3 in both cases for significantly faster iteration over the potential inputs. The scripts also partition their work against 8 CPU threads, which should be tweaked depending on target hardware and impatience level.
Finding Input Hash Solutions
The xxhash(ish) system used on the user input functions at a fundamental level like the following:
Input Lo Input Hi Hash Out
S1 --------> ⊕ --------> ⊕ --------> ⊕
V
S2 --------> ⊕ --------> ⊕ --------> ⊕
V
S3 --------> ⊕ --------> ⊕ --------> ⊕
V
S4 --------> ⊕ --------> ⊕ --------> ⊕
V
C1 ----------------------------------> ⊕
S1-4 Represent constant state inputs hashed from a hardcoded string in the application: “Look at you, hacker. A pathetic creature of meat and bone, panting and sweating as you run through my corridor. How can you challenge a perfect immortal machine?”
C1 is a constant based on the amount of input into the system. Input hi and lo are 32 bytes of in-order user input split into DWORD sized chunks.
Even when constrained to limited character sets, the precision loss and input flexibility mean there are simply too many solutions to find the original ‘wisdom’ the author intended - but better to have too many solutions than too few 🙂
I chose to solve for a valid hash using z3, the flexibility of the inputs meant I could impart a bit of my own wisdom in the solution. The script replicates the hashing algorithm and targets an output state of our desired PRNG seed.
from z3 import *
def bit_mirror(bv, width=32):
bits = []
if width == 32:
for i in range(width):
bits.append(Extract(i, i, bv))
return Concat(*bits)
elif width == 16:
for i in range(16):
bits.append(Extract(i, i, bv))
return Concat(Extract(31, 16, bv), *bits)
elif width == 8:
for i in range(8):
bits.append(Extract(i, i, bv))
return Concat(Extract(31, 8, bv), *bits)
def byte_swap(bv, width=32):
if width == 32:
return Concat(Extract(15, 0, bv), Extract(31, 16, bv))
elif width == 16:
return Concat(Extract(31, 16, bv), Extract(7, 0, bv), Extract(15, 8, bv))
elif width == 8:
return Concat(Extract(31, 8, bv), Extract(3, 0, bv), Extract(7, 4, bv))
else:
raise ValueError('Invalid width for byte_swap')
def xx_round(r0, state, rotate: int):
r4 = byte_swap(byte_swap(byte_swap(state), 8), 16)
r4 = bit_mirror(r4)
r4 = byte_swap(byte_swap(byte_swap(r4, 16), 8))
if rotate < 0:
return r0 ^ RotateLeft(r4, -rotate)
else:
return r0 ^ RotateRight(r4, rotate)
def xx_update(states, inputs):
new_states = []
for i in range(4):
r4 = states[i]
r8 = byte_swap(inputs[i]) ^ 0x85EBCA77
r8 = byte_swap(r8, 16)
r8 = bit_mirror(r8, 16)
r8 = byte_swap(r8, 8)
r8 = bit_mirror(r8, 8)
r8 = byte_swap(r8)
r8 = bit_mirror(r8)
r4 = RotateLeft(r4 ^ r8, 0xD) ^ 0x9E3779B1
r4 = bit_mirror(r4)
r4 = byte_swap(r4)
r4 = byte_swap(r4, 16)
r4 = bit_mirror(r4, 16)
r4 = bit_mirror(r4, 8)
r4 = byte_swap(r4, 8)
new_states.append(r4)
return new_states
s = Solver()
zero_vec = BitVec('zero_vec', 32)
s.add(zero_vec == 0)
in_vecs = BitVecs('in_vec_1 in_vec_2 in_vec_3 in_vec_4 in_vec_5 in_vec_6 in_vec_7 in_vec_8', 32)
for in_vec in in_vecs:
for i in range(4):
cond = (in_vec >> (i * 8)) & 0xFF
s.add(And(cond > 0x20, cond < 0x7A))
s.add((in_vecs[0] >> 24) & 0xFF == ord('n'))
s.add((in_vecs[0] >> 16) & 0xFF == ord('4'))
s.add((in_vecs[0] >> 8) & 0xFF == ord('k'))
s.add((in_vecs[0] >> 0) & 0xFF == ord('3'))
s.add((in_vecs[1] >> 24) & 0xFF == ord('d'))
s.add((in_vecs[1] >> 16) & 0xFF == ord('_'))
s.add((in_vecs[1] >> 8) & 0xFF == ord('t'))
s.add((in_vecs[1] >> 0) & 0xFF == ord('4'))
s.add((in_vecs[2] >> 24) & 0xFF == ord('X'))
s.add((in_vecs[2] >> 16) & 0xFF == ord('_'))
s.add((in_vecs[2] >> 8) & 0xFF == ord('f'))
s.add((in_vecs[2] >> 0) & 0xFF == ord('R'))
s.add((in_vecs[3] >> 24) & 0xFF == ord('a'))
s.add((in_vecs[3] >> 16) & 0xFF == ord('u'))
s.add((in_vecs[3] >> 8) & 0xFF == ord('D'))
s.add((in_vecs[3] >> 0) & 0xFF == ord('!'))
# Initial xx state
E1004 = 0x6123f3e9
E1008 = 0xfffb8a27
E100C = 0xca1590f0
E1010 = 0xcaf09150
E1004, E1008, E100C, E1010 = xx_update(
[E1004, E1008, E100C, E1010],
[in_vecs[0], in_vecs[1], in_vecs[2], in_vecs[3]])
E1004, E1008, E100C, E1010 = xx_update(
[E1004, E1008, E100C, E1010],
[in_vecs[4], in_vecs[5], in_vecs[6], in_vecs[7]])
# xxfinish
r0 = xx_round(zero_vec, E1004, 0x1F)
r0 = xx_round(r0, E1008, -0x7)
r0 = xx_round(r0, E100C, 0x14)
r0 = xx_round(r0, E1010, -0x12)
r0 = r0 ^ 0x00400000 # constant counter state
r0 = bit_mirror(r0 ^ RotateRight(r0, 0xF)) ^ 0x85EBCA77
r0 = bit_mirror(r0 ^ RotateRight(r0, 0xD)) ^ 0xC2B2AE3D
r0 = r0 ^ RotateRight(r0, 0xD)
s.add(r0 == 0xb48db866) # Target PRNG state
while s.check() == sat:
m = s.model()
secret = b''
for i, in_vec in enumerate(in_vecs):
secret += m[in_vec].as_long().to_bytes(4, 'big')
print(f"secret = {secret.decode()}")
Wrap-up
I asked Ben_Lolo what the intended flag was after finding my solutions, and he was kind enough to share ~~-_B-l()yAl-2_W@T_mAtT3R5_-~~, but I have to admit I am slightly partial to the ones I found.
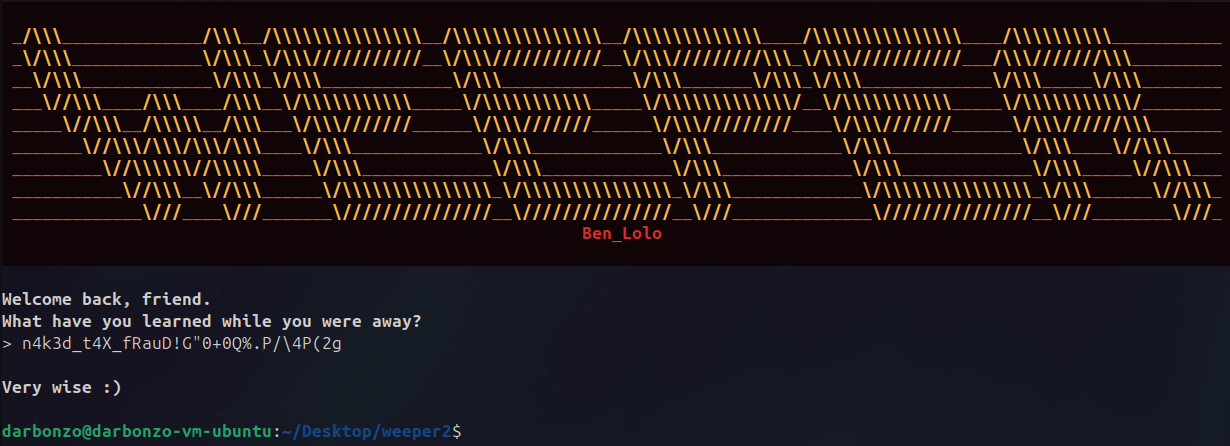
🎉🎉 happy hacking, until next time 🎉🎉
darbonzo